
Yapay zeka, ne bildiğini değil, neye dayanarak konuştuğunu yeniden tanımlayan bir yaklaşım gerektirir.
Büyük dil modelleri yalnızca eğitim verileri kadar konuşabilir; eğitim sonrası değişen bilgiler, kuruma
özgü dokümanlar veya güncel regülasyonlar devreye girdiğinde model ya yanlış bilgi üretir ya da belirsizleşir. Retrieval-Augmented Generation (RAG), bu kısıtı aşmak için yanıt üretmeden önce dış bir
bilgi kaynağından ilgili içerikleri bulup getirerek üretimi kanıta dayalı hâle yaklaştırır.
Akademik alanda RAG; halüsinasyon azaltma, kaynak gösterilebilir yanıt üretimi ve bilgiye dayalı doğal
dil üretimi başlıklarında önemli bir köprü kurar. Endüstride değer daha somuttur: müşteri destek
botlarının ürün dokümantasyonuna dayanması, hukuk ve uyum ekiplerinin güncel düzenlemelerle
çalışması, satış ekiplerinin doğru fiyat ve özellik bilgisiyle konuşması ya da iç denetimde politikaların
hızlıca bulunup özetlenmesi bunların yalnızca birkaçıdır. Üstelik modeli yeniden eğitmeden bilgi
güncellenebilir; bu da hem maliyet hem de operasyonel yükü ciddi ölçüde azaltır.
Ancak RAG projelerinin başarısını çoğu zaman belirleyen soru şudur: “Hangi modeli seçtik?” değil, “Arama katmanını ölçebiliyor muyuz?” Bu yazı, bu soruya operasyonel bir yanıt vermek için tasarlanmış bir değerlendirme çerçevesi önerir.
RAG Mimarisi: Neden İki Katman Ayrı Ele Alınmalı?
RAG'i iki ayrı katman olarak modellemek, hem ölçüm hem de hata ayıklama süreçlerinde kritik bir avantaj sağlar. İlk katman olan retrieval; sorguyu bir arama problemine dönüştürür, doküman havuzu, vektör veri tabanı, wiki sayfaları, destek kayıtları veya mevzuat metinleri içinde en alakalı parçaları (chunk) seçer. Bu adım tamamen mühendislik sorunudur ve model davranışından bağımsız biçimde ölçülebilir. İkinci katman olan generation ise büyük dil modelinin bu parçaları bağlam olarak kullanarak yanıt ürettiği kısımdır.
İki katmanın birbirinden bağımsız değerlendirilebilmesi, hata kaynağının doğru tanımlanması açısından vazgeçilmezdir. “Yanıt yanlış” gözlemi tek başına bir eylem planı doğurmaz. Ancak “Retrieval Recall@5 = 0.62” gözlemi doğrudan müdahale noktasını gösterir. Çoğu ekip her şeyi modele yükler; oysa bazen çözüm daha iyi parçalama, daha temiz erişim yetkileri, daha doğru indeksleme ya da çelişki yakalayan basit bir doğrulama adımındadır.
Gerçek Dünyadan: Bir Regülasyon Uyum Sistemi
Aşağıdaki deneyim, kişisel olarak dahil olduğum bir RAG geliştirme sürecinden anonim biçimde aktarılmıştır.
Çok sayıda ülkede faaliyet gösteren bir finansal hizmetler ortamında, hukuk ve uyum ekipleri için dahili bir RAG sistemi kuruluyordu. Kaynak külliyatı; farklı dillerde yazılmış dört bini aşkın düzenleyici doküman, sirküler ve içtihat metninden oluşuyordu. İlk prototip yüksek kaliteli bir dil modeli kullanmasına rağmen, uzman kullanıcılar yanıtların önemli bir bölümünü güvenilmez buluyordu. Sorun başlangıçta modele yüklendi ve model değiştirildi. Fark ihmal düzeyindeydi.
Sistematik ölçüm uygulandığında tablo net biçimde ortaya çıktı. Retrieval Recall@5 değeri 0.58'di; yani doğru düzenleyici metnin yalnızca yüzde elli sekizi ilk beş sonuç içinde yer alıyordu. Chunk boyutu bin yirmi dört token olarak ayarlanmıştı ve birden fazla madde içeren uzun pasajlar tek bir parçaya sıkıştırıldığından semantik özgüllük kaybolmuştu. Staleness Age ise yüz yirmi yedi gündü: index güncelleme pipeline'ı kesintiye uğramış, sistemin yanıt verdiği bazı mevzuat metinleri bu arada revize edilmişti.
Modeli değiştirmek gerekmedi. Üç müdahale yeterliydi: chunk boyutu iki yüz elli altı token'a düşürüldü ve sliding window örtüşme eklendi; tarih filtresi retrieval katmanına eklenerek yalnızca son altmış gün içinde indekslenmiş dokümanlar önceliklendi; kaynak hash izleme ile delta-index pipeline'ı otomatikleştirildi. Sekiz hafta içinde Recall@5 değeri 0.87'ye yükseldi. Uzman kullanıcı güven skoru 2.9'dan 4.3'e çıktı, hukuk ekibinin ortalama araştırma süresi yüzde otuz dört azaldı. Bu iyileştirmelerin hiçbirinde model katmanına dokunulmadı.
Temel çıkarım: RAG başarısızlıklarının büyük çoğunluğu retrieval katmanındadır ve ölçülmeden çözülemez.
RAG Değerlendirme Çerçevesi (REF)
Mevcut literatür retrieval ve generation metriklerini çoğunlukla ayrı ayrı ele almaktadır. Ancak pratikte bu metriklerin birlikte yorumlanması, operasyonel kararlar için bir tanı akışı oluşturulması ve sistemin yaşam döngüsü boyunca izlenmesi gerekmektedir. RAG Değerlendirme Çerçevesi (REF), bu üç ekseni bütünleştiren sistematik bir değerlendirme çerçevesidir.
Metrikler ve Operasyonel Tanımları
REF dokuz boyutu kapsar ve her birini “nasıl ölçülür", “kabul eşiği” ve “düşük skorun anlamı” eksenlerinde tanımlar. Retrieval kalitesi için Recall@K ve MRR (Mean Reciprocal Rank); yanıt kalitesi için Groundedness, Kaynak Kapsamı ve Çelişki Skoru; sistem sağlığı için p95 gecikme ve istek başı maliyet; güncellik için Staleness Age; güven için ise haftalık insan örnekleme skoru izlenir. Groundedness ve Çelişki Skoru hesaplamasında NLI (Natural Language Inference) modeli —örneğin cross-encoder/nli-deberta-v3-base— kullanılabilir; her iki ölçüm de aynı model üzerinden yapılabildiğinden altyapı maliyeti düşüktür.
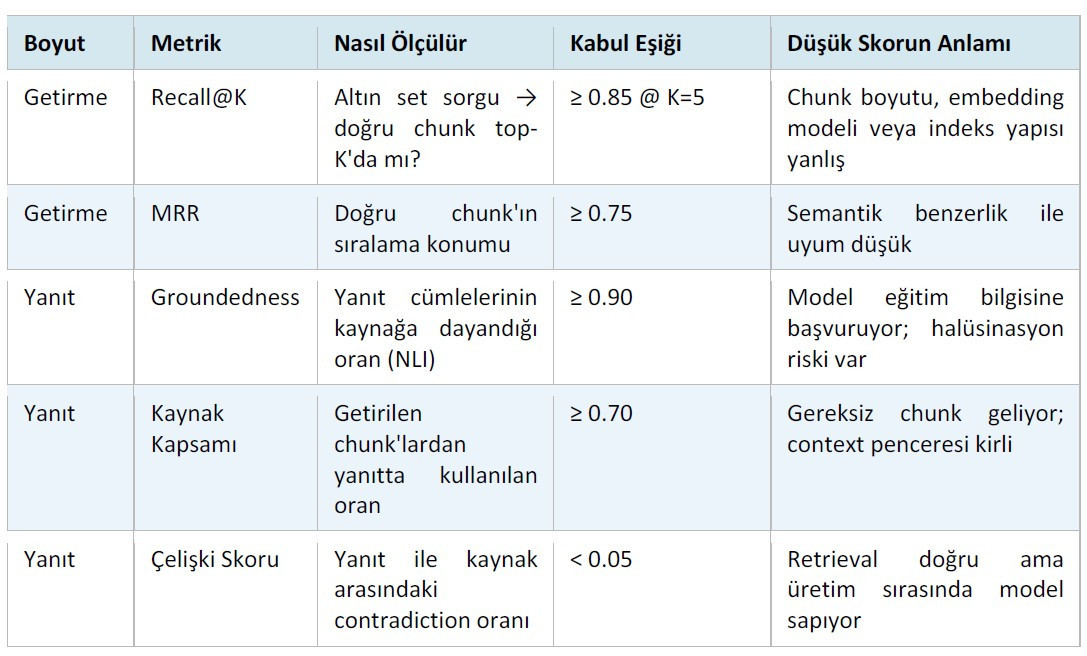
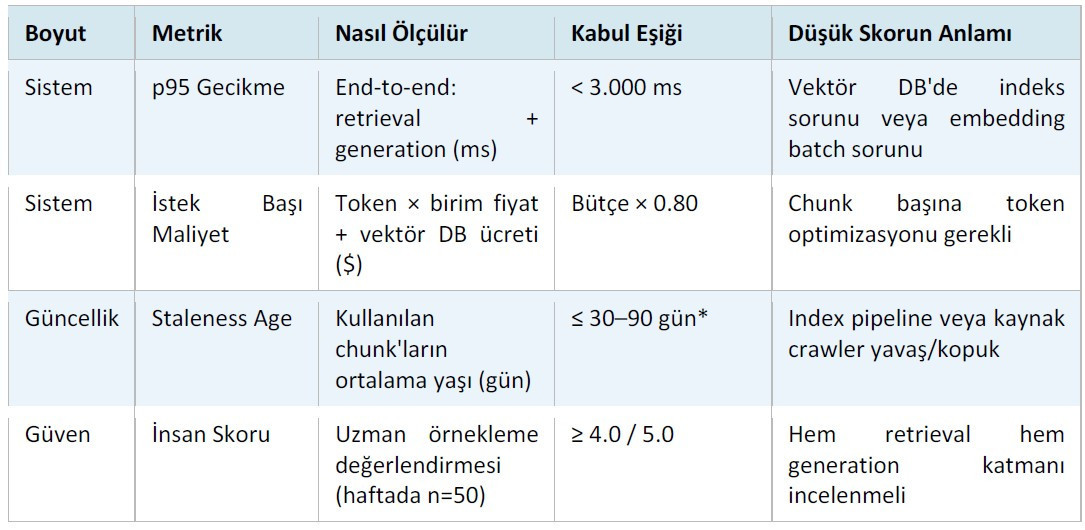
* Staleness Age eşiği sektöre göre değişir. Hukuk ve finans gibi hızlı değişen düzenleyici ortamlarda otuz gün, daha durağan kaynaklarda doksan güne kadar çıkabilir.
Altın Değerlendirme Seti
REF'in işletilebilmesi için üretime geçmeden önce bir altın değerlendirme seti oluşturulmalıdır. Bu set; gerçek kullanıcı sorgularından örneklenmiş ya da konu uzmanlarınca hazırlanmış yüz ile üç yüz arasında soru-cevap çiftini kapsamalı ve her soru için ground truth chunk referanslarını içermelidir. Settin temsil edici olması için yalnızca kolay sorular değil, kenar durumlar, çelişkili dokümanlar ve güncelliğini yitirmiş bilgilere atıfta bulunan sorgular da dahil edilmelidir. Kaynak külliyatı her güncellendiğinde set sistematik biçimde revize edilmeli; aksi hâlde metrikler zamanla anlamlılığını yitirir.
Tanı Akışı
REF'in pratikteki gücü, salt ölçümden değil metriklerin birlikte yorumlanmasından gelir. Recall@5 düşükken Groundedness'ı optimize etmek anlamsızdır; hata retrieval katmanındadır ve orası düzeltilmeden generation katmanına yapılacak her müdahale geçici bir çözüm olmaktan öteye geçemez. Aşağıdaki tablo, sık karşılaşılan sinyal kombinasyonlarını kök neden ve müdahale noktasıyla eşleştirir:
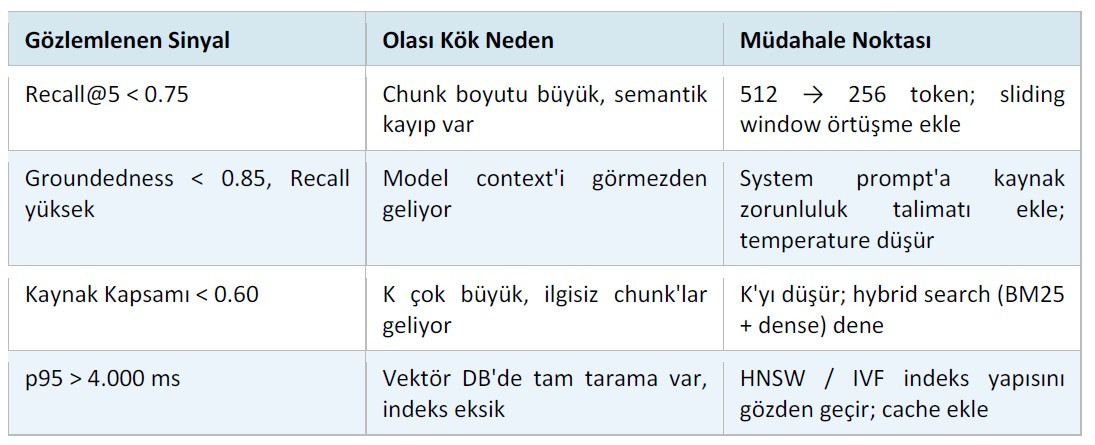

Sürekli İzleme Döngüsü
REF yalnızca üretime almadan önce değil, üretim boyunca da işletilmelidir. Anlık metrikler olarak p95 gecikme ve istek başı maliyet her üretim isteğinde loglanır. Her index güncellemesinde altın set üzerinden Recall@K ve Groundedness otomatik çalıştırılır. Haftalık uzman örneklemesiyle elli yanıt değerlendirilir ve insan skoru trendlere kaydedilir. Aylık staleness denetiminde tüm chunk'ların güncelleme tarihleri raporlanır; eşiği aşan kaynaklar re-index kuyruğuna alınır. Bu döngü, RAG sistemini “bir kere kur ve unut” yaklaşımından çıkararak yaşayan ve ölçülen bir sistem hâline getirir.
Gözden Kaçan Boyut: Veri Yönetişimi
Teknik metrikler ne kadar olgunlaşırsa olsun, veri yönetişimi sorunları RAG'i hızlı bir yanlış üretim hattına dönüştürebilir. Retrieval sistemi, kullanıcının erişim yetkisi olmadığı dokümanları getirmemelidir; chunk düzeyinde erişim denetimi kurumsal sistemlerde zorunluluktur. Arşivlenen veya geçerliliğini yitiren dokümanlar index'ten temizlenmeli; aksi hâlde “silinen” politikalar yanıtlara yansımaya devam eder.
Hangi chunk'ların hangi yanıta katkıda bulunduğu loglanmalıdır; bu hem uyum denetimleri hem de sistem güveni açısından kritik bir gerekliliktir. Vektörleştirilmiş embedding'lerin de geri-dönüşüm saldırılarına karşı savunmasız olabileceği unutulmamalıdır. Hassas veri içeren dokümanlar için ek şifreleme katmanı değerlendirilmelidir. Veri gizliliği, loglama ve kaynak yaşam döngüsü yönetilmedikçe REF metrikleri yeşil görünse bile sistem güvenilirliği bir yanılsama olmaktan öteye geçemez.
Ajanlaşan RAG: Bir Sonraki Eşik
Mevcut RAG implementasyonlarının büyük çoğunluğu reaktif bir döngüde çalışır: sorgu gelir, chunk seçilir, yanıt üretilir. Ancak bu mimari, belirsiz ya da çok adımlı sorguların önünde yapısal bir tavan oluşturur. Bir sonraki nesil sistemlerde model yalnızca metin getirmekle kalmayacak; sorguyu iyileştirecek, farklı kaynakları karşılaştıracak, çelişkileri işaretleyecek ve gerektiğinde “Bu soruya güvenilir bir yanıt üretemiyorum” diyerek insan onayı isteyecek.
Self-RAG benzeri döngülerde üretilen yanıt aynı retrieval pipeline'ına geri beslenerek tutarlılık doğrulanabilir. Çok kaynaklı karşılaştırma ile farklı tarih veya yetki alanından gelen chunk'lar arasındaki çelişkiler otomatik işaretlenebilir. Bu özelliklerin REF metrikleriyle uyumlu biçimde tasarlanması, ajanlaşan RAG sistemlerini hem daha yetenekli hem de denetlenebilir kılar. Belirsizlik sinyali özelliği ise REF'teki Groundedness ve Çelişki Skoru eşiklerine bağlanarak doğrudan operasyonel hale getirilebilir: eşik altında kalan her yanıt otomatik olarak insan onayı kuyruğuna alınabilir.
Sonuç
RAG, üretken yapay zekâyı gösterişli bir konuşmacıdan kurumsal hafızayla çalışan güvenilir bir asistana taşıyan en güçlü köprülerden biridir. Ancak bu geçişin gerçekleşebilmesi için RAG'in bir prompt yazma problemi gibi değil, ölçülebilir bir geri çağırma ve doğrulama problemi olarak ele alınması şarttır. RAG Değerlendirme Çerçevesi (REF), bu ihtiyaca sistematik bir yanıt sunmaktadır. Retrieval Recall, Groundedness, Kaynak Kapsamı, Çelişki Tespiti, gecikme, maliyet ve staleness gibi metriklerin bütünleşik yorumu, ekiplerin hata kaynağını doğru tanımlamasını ve müdahale noktasını isabetli seçmesini sağlar. Regülasyon uyum vakasında görüldüğü üzere, doğru ölçüm olmadan model değişikliği boşuna yapılan bir operasyondan ibarettir; doğru ölçümle ise model katmanına hiç dokunmadan sistemin güvenilirliği köklü biçimde artırılabilir. En güçlü RAG sistemi en büyük modeli kullanan değil, retrieval katmanını en iyi ölçen ve buna göre iteratif biçimde iyileştiren sistemdir.
Hakan Baysal